
Sự phát triển của Trí tuệ Nhân tạo, đặc biệt là trong lĩnh vực Xử lý Ngôn ngữ Tự nhiên đã đạt được những bước tiến vượt bậc trong thập kỷ qua. Nền tảng của sự tiến bộ này chính là Mô hình Ngôn ngữ, hay còn được gọi là Language Model (LM). Để hiểu rõ về tác động sâu rộng của AI tạo sinh, hãy cùng FOXAi khám phá Language Model là gì? Khái niệm, cách hoạt động, ứng dụng trong bài viết dưới đây.
Language Model là gì?
Khái niệm
Mô hình Ngôn ngữ (LM) là một mô hình toán học hoặc thống kê được thiết kế để dự đoán từ tiếp theo trong một chuỗi văn bản hoặc để xác định xác suất xuất hiện của một chuỗi từ nhất định. Nói cách khác, chức năng cơ bản của LM là học các quy tắc ngữ pháp, ngữ nghĩa và ngữ cảnh từ một tập dữ liệu lớn, cho phép máy tính hiểu và tạo ra ngôn ngữ giống con người. Chính vì vậy, LM là nền tảng cơ bản cho hầu hết các hệ thống NLP và AI tạo sinh hiện nay.
Ví dụ như về mặt toán học, mô hình ngôn ngữ giúp tính xác suất p(x₁…xₙ) của một chuỗi từ, về mặt ngữ nghĩa giúp xác định câu nào phù hợp hơn với một ngôn ngữ (ví dụ: “em đang sử dụng máy tính” có xác suất cao hơn “tính máy dụng sử đang em”).
Vai trò của Language Model trong AI
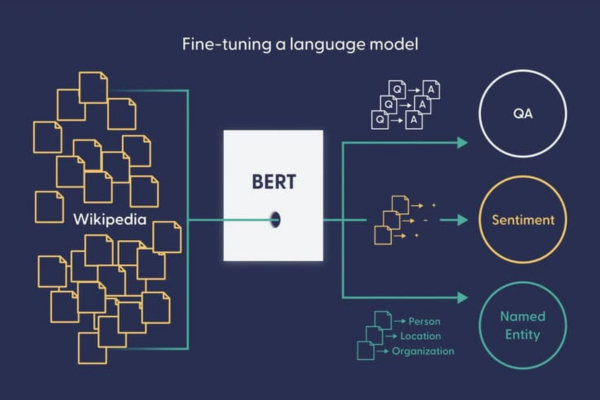
Mô hình Ngôn ngữ đóng vai trò trung tâm trong NLP, giúp máy tính vượt qua rào cản kỹ thuật để có thể hiểu và sử dụng ngôn ngữ con người. Sự ra đời của LLM (Large Language Model) đã mở ra một kỷ nguyên mới cho AI giao tiếp. Các mô hình này không chỉ cải thiện hiệu suất của các ứng dụng truyền thống như dịch thuật và hoàn thiện câu mà còn nâng cao đáng kể khả năng của các trợ lý ảo tự động (như Google Assistant và Siri). Cụ thể, LLM cho phép các trợ lý ảo này diễn giải ý định phức tạp của người dùng một cách tốt hơn và phản hồi các lệnh một cách tự nhiên và chính xác hơn.
Vai trò của LLM đang dần được chuyển từ công cụ xử lý văn bản thành phương tiện giao tiếp cốt lõi. Mục tiêu phát triển trong tương lai không chỉ dừng lại ở việc tạo ra văn bản một chiều mà còn hướng tới khả năng đối thoại tương tác với con người một cách hoàn toàn tự nhiên. Điều này đòi hỏi các mô hình phải chú trọng hơn vào việc đảm bảo tính minh bạch, an toàn và tạo ra đầu ra chính xác trong quá trình xử lý thông tin. Khả năng chuyển đổi từ AI công cụ sang AI đồng hành, có khả năng tương tác sâu, đồng thời cũng là yếu tố then chốt định hình lại cách các doanh nghiệp tương tác với khách hàng và quản lý nội dung.
Cách thức hoạt động của Language Model
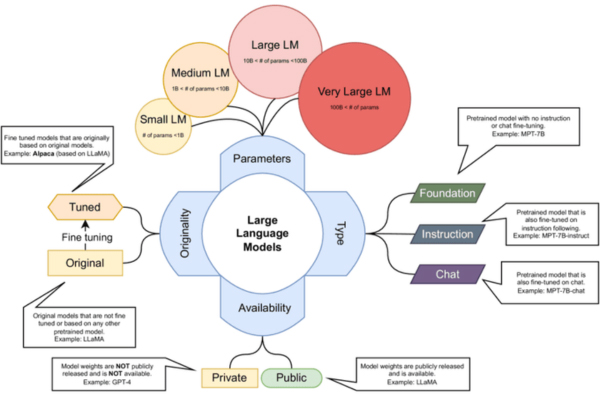
Các mô hình ngôn ngữ (Language Model) hoạt động bằng cách phân tích lượng dữ liệu văn bản khổng lồ để nhận diện mẫu ngôn ngữ và quy luật xuất hiện của từ, từ đó ước tính xác suất của từng từ trong ngữ cảnh cụ thể. Thông qua các thuật toán học máy, mô hình học được cấu trúc, đặc điểm và mối liên hệ giữa các từ, đồng thời hiểu cách con người sử dụng ngôn ngữ tự nhiên. Sau quá trình huấn luyện, mô hình áp dụng kiến thức đã học vào nhiều tác vụ khác nhau như dự đoán từ tiếp theo, hoàn thiện câu, hoặc tạo ra cụm từ, câu, đoạn văn mới có ý nghĩa.
Tùy theo mục đích sử dụng, mỗi mô hình được thiết kế theo cách riêng. Ví dụ, trợ lý ảo như Siri cần phản hồi gần như tức thì, nên sử dụng kiến trúc tính toán tối ưu cho tốc độ, trong khi mô hình phục vụ viết nội dung dài lại tập trung vào tính liền mạch và mạch ngữ nghĩa.
Về mặt kỹ thuật, điểm khác biệt giữa các mô hình nằm ở ba yếu tố chính:
- Khối lượng và độ đa dạng của dữ liệu huấn luyện.
- Phương pháp và thuật toán thống kê hoặc học sâu được áp dụng.
- Khả năng xử lý ngữ cảnh đa tầng, từ mối quan hệ giữa các từ liền kề đến việc hiểu ý nghĩa tổng thể của đoạn hoặc văn bản dài.
Nhờ đó, các hệ thống ngôn ngữ thế hệ mới có thể tạo ra nội dung tự nhiên, mạch lạc và gần với cách con người giao tiếp hơn bao giờ hết.
Một số loại Language Model phổ biến
Một số loại Language Model phổ biến bạn có thể ứng dụng để xây dựng mô hình ngôn ngữ, bao gồm:
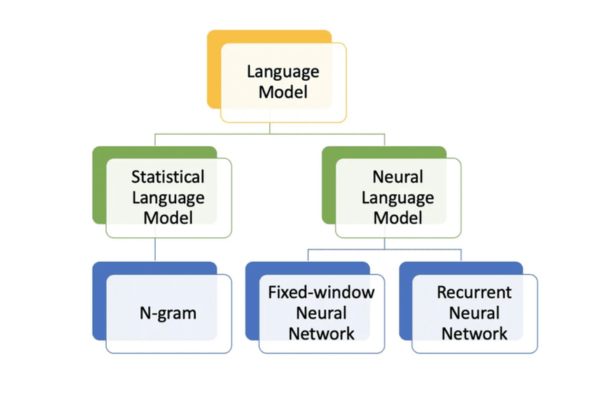
N-gram
Là phương pháp xây dựng mô hình ngôn ngữ dựa trên việc xác định phân phối xác suất cho các chuỗi gồm n phần tử liên tiếp, có thể là từ, ký tự hoặc biến đã được gán xác suất. Tham số n thể hiện độ dài chuỗi, đồng thời xác định phạm vi ngữ cảnh mà mô hình sử dụng để dự đoán từ kế tiếp. Ví dụ, với câu “bạn có thể gọi cho tôi” và n = 5, chuỗi N-gram tương ứng là “bạn có thể gọi cho”. Mô hình sẽ tính toán xác suất để từ “tôi” xuất hiện tiếp theo, dựa trên ngữ cảnh của bốn từ trước đó.

Các dạng N-gram phổ biến bao gồm:
- Unigram (n = 1): Xem xét từng từ độc lập.
- Bigram (n = 2): Phân tích các cặp từ liền kề.
- Trigram (n = 3): Xem xét nhóm ba từ liên tiếp.
Bên cạnh khả năng dự đoán từ kế tiếp trong văn bản, N-gram còn được ứng dụng trong phát hiện phần mềm độc hại, thông qua việc phân tích chuỗi byte lặp lại trong các tệp thực thi để nhận diện hành vi đáng ngờ.
Unigram
Unigram là dạng mô hình ngôn ngữ cơ bản nhất, trong đó mỗi từ hoặc thuật ngữ được đánh giá độc lập, không phụ thuộc vào ngữ cảnh xung quanh. Khác với các mô hình phức tạp hơn, Unigram không tính đến mối quan hệ giữa các từ, mà chỉ tập trung vào xác suất xuất hiện riêng lẻ của từng từ trong tập dữ liệu.
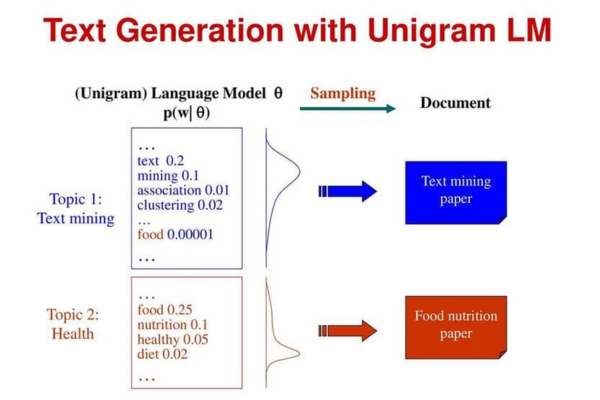
Phương pháp này thường được ứng dụng trong truy xuất thông tin và là nền tảng của các mô hình xác suất truy vấn, giúp hệ thống xác định và xếp hạng các tài liệu phù hợp nhất với một truy vấn cụ thể dựa trên tần suất và mức độ liên quan của từ khóa.
Mô hình hai chiều (Bidirectional)
Mô hình này khác với N-gram ở chỗ nó phân tích văn bản theo cả hai hướng – từ trái sang phải và từ phải sang trái – thay vì chỉ một chiều. Nhờ đó, mô hình có khả năng dự đoán chính xác hơn khi xác định một từ bất kỳ trong câu dựa trên toàn bộ ngữ cảnh xung quanh.

Cách tiếp cận này đặc biệt hiệu quả trong các bài toán học máy (Machine Learning) và ứng dụng AI tạo giọng nói, nơi yêu cầu hiểu sâu cấu trúc ngôn ngữ. Chẳng hạn, Google đã áp dụng mô hình hai chiều để xử lý và hiểu rõ hơn truy vấn tìm kiếm của người dùng, giúp cải thiện độ chính xác của kết quả.
Hàm mũ (Exponential Model)
Hàm mũ hay còn được gọi là mô hình entropy tối đa, là phiên bản nâng cao và phức tạp hơn N-gram. Thay vì chỉ dựa vào các chuỗi từ liền kề, mô hình này kết hợp nhiều hàm đặc trưng cùng N-gram để đánh giá văn bản. Nó xác định các đặc trưng và tham số của kết quả mong muốn, nhưng không giới hạn trong kích thước gram cố định, cho phép linh hoạt hơn trong phân tích.
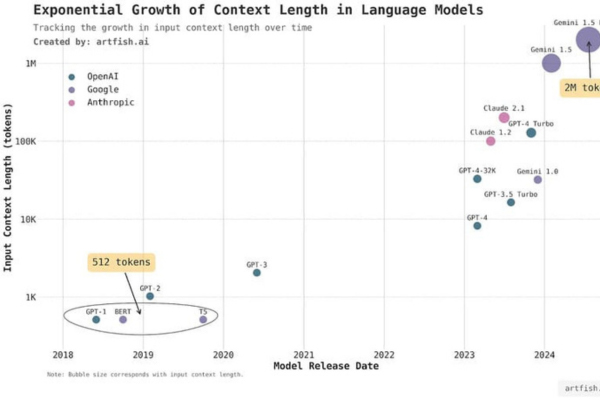
Nguyên lý cốt lõi của Exponential Model dựa trên entropy, trong đó, phân phối xác suất có entropy cao nhất được xem là tối ưu nhất. Nói cách khác, mô hình càng “tự do”, ít giả định trước, thì kết quả càng có độ chính xác cao.
Các mô hình hàm mũ thường được xây dựng nhằm tối đa hóa cross-entropy, giúp giảm thiểu các giả định thống kê, từ đó nâng cao khả năng khái quát và độ tin cậy khi xử lý ngôn ngữ tự nhiên.
Mô hình ngôn ngữ Neural (Neural Language Model)
Mô hình ngôn ngữ Neural áp dụng công nghệ học sâu (Deep Learning) nhằm khắc phục những hạn chế của mô hình N-gram truyền thống. Thay vì chỉ dựa trên xác suất của các chuỗi từ cố định, mô hình này sử dụng mạng nơ-ron nhân tạo như Recurrent Neural Network (RNN) và Transformer để nhận diện các mẫu ngôn ngữ phức tạp và mối quan hệ phụ thuộc dài hạn trong văn bản.
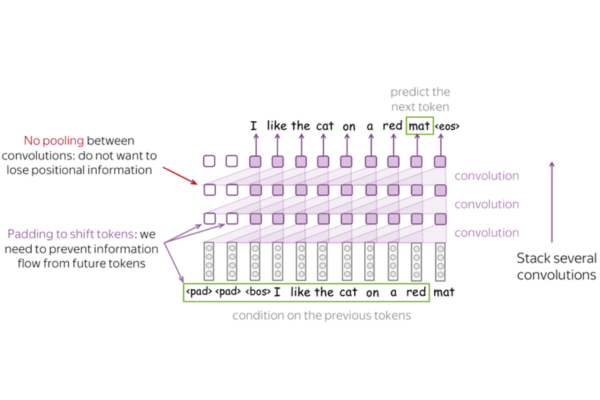
Trong đó, các biến thể của RNN như LSTM (Long Short-Term Memory) và GRU (Gated Recurrent Unit) cho phép mô hình ghi nhớ thông tin từ những từ xuất hiện trước đó, nhờ vậy có thể dự đoán từ tiếp theo chính xác hơn và duy trì tính mạch lạc theo ngữ cảnh.
Ngược lại, Transformer hoạt động dựa trên cơ chế tự chú ý (Self-Attention) – giúp đánh giá mức độ ảnh hưởng của từng từ trong toàn bộ câu, từ đó nắm bắt các quan hệ ngữ nghĩa trên phạm vi toàn cục. Nhiều mô hình AI tạo sinh hiện đại, chẳng hạn như GPT-3 hay PaLM 2, đều được xây dựng dựa trên kiến trúc Transformer, minh chứng cho khả năng ưu việt của mô hình ngôn ngữ Neural trong việc hiểu và tạo lập ngôn ngữ tự nhiên.
Mô hình Không gian liên tục (Continuous Space Model)
Mô hình Không gian liên tục là một dạng mạng nơ-ron (neural network) trong đó mỗi từ được biểu diễn bằng tổ hợp phi tuyến tính của các trọng số trong mạng. Quá trình gán các trọng số này được gọi là nhúng từ (word embedding) – một bước quan trọng giúp mô hình hiểu được mối quan hệ ngữ nghĩa giữa các từ trong không gian nhiều chiều.
Khác với các mô hình tuyến tính như N-gram, vốn gặp khó khăn khi xử lý tập dữ liệu lớn có nhiều từ hiếm hoặc ít xuất hiện, mô hình không gian liên tục có khả năng học và suy diễn linh hoạt hơn. Nhờ cách biểu diễn phi tuyến và phân tán, nó có thể xấp xỉ ý nghĩa của từ dựa trên ngữ cảnh tổng thể mà không phụ thuộc cứng nhắc vào các từ liền kề.
Cách tiếp cận này giúp mô hình duy trì độ chính xác và khả năng khái quát hóa cao, đồng thời khắc phục hiện tượng suy giảm hiệu suất thường thấy trong các mô hình tuyến tính khi độ dài chuỗi văn bản tăng lên.
Các Language Model có mức độ phức tạp khác nhau, và thông thường, mô hình càng tinh vi thì khả năng xử lý ngôn ngữ tự nhiên (NLP) càng hiệu quả. Bởi ngôn ngữ con người vốn đa dạng, mơ hồ và không ngừng thay đổi, đòi hỏi hệ thống phải có khả năng hiểu sâu sắc hơn thay vì chỉ ghi nhớ các mẫu đơn giản.
Một mô hình ngôn ngữ chất lượng cao cần được thiết kế để giải quyết sự mơ hồ ngữ nghĩa, nhận biết các biến thể ngôn ngữ và nắm bắt được các mối liên hệ dài hạn trong văn bản. Điều này bao gồm khả năng hiểu khi một từ hoặc cụm từ đang tham chiếu đến yếu tố xuất hiện từ xa trong câu hoặc đoạn trước đó, thay vì chỉ dựa trên bối cảnh cục bộ hoặc chuỗi từ gần kề.
Ứng dụng và ví dụ của Language Model
Các mô hình ngôn ngữ được xem là nền tảng cốt lõi của các ứng dụng xử lý ngôn ngữ tự nhiên. Chúng đóng vai trò như “bộ não” giúp máy tính hiểu, tạo và tương tác bằng ngôn ngữ con người. Dưới đây là một số ứng dụng và nhiệm vụ tiêu biểu dựa trên Language Modeling:
Nhận diện giọng nói (Speech Recognition): Giúp máy tính hiểu và xử lý âm thanh lời nói của con người. Công nghệ này là nền tảng của các trợ lý ảo phổ biến như Siri, Alexa hay Google Assistant.
Sinh văn bản (Text Generation): Dựa trên khả năng dự đoán từ ngữ, mô hình tạo ra văn bản liền mạch, phù hợp với ngữ cảnh, thường được ứng dụng trong viết sáng tạo, tạo nội dung tự động hoặc tóm tắt dữ liệu có cấu trúc.
AI Chatbot: Các chatbot sử dụng Language Model để duy trì hội thoại tự nhiên, phản hồi chính xác và có ngữ cảnh, phục vụ trong chăm sóc khách hàng, trợ lý ảo và hệ thống tìm kiếm thông tin thông minh.
Dịch máy (Machine Translation): Chuyển đổi ngôn ngữ nhanh chóng và chính xác, được ứng dụng trong các công cụ như Google Dịch, Microsoft Translator, hay các hệ thống chuyên dụng như SDL Government phục vụ dịch dữ liệu mạng xã hội thời gian thực cho chính phủ Hoa Kỳ.
Gắn thẻ từ loại (Part-of-Speech Tagging): Phân loại các từ theo chức năng ngữ pháp của chúng (danh từ, động từ, tính từ,…). Một ví dụ nổi bật là nghiên cứu Brown Corpus, nền tảng cho nhiều mô hình ngôn ngữ hiện đại, bao gồm cả mô hình của Google nhằm cải thiện chất lượng kết quả tìm kiếm.
Phân tích cú pháp (Parsing): Xây dựng cấu trúc cú pháp cho câu, xác định mối quan hệ giữa các từ. Kỹ thuật này thường được ứng dụng trong kiểm tra chính tả và ngữ pháp tự động.
Nhận dạng ký tự quang học (OCR – Optical Character Recognition): Biến hình ảnh chứa văn bản (như tài liệu được quét hoặc ảnh chụp) thành văn bản kỹ thuật số, hỗ trợ số hóa tài liệu, nhận dạng chữ viết tay hoặc lưu trữ dữ liệu hiệu quả hơn.
Truy xuất thông tin (Information Retrieval): Giúp tìm kiếm dữ liệu hoặc siêu dữ liệu liên quan trong kho tài liệu lớn. Công cụ tìm kiếm web chính là ví dụ điển hình của ứng dụng này.
Phân tích dữ liệu quan sát (Observational Data Analysis): Sử dụng mô hình ngôn ngữ để giải thích và khai thác dữ liệu cảm biến, dữ liệu đo đạc, hoặc dữ liệu thí nghiệm, giúp phát hiện mẫu hoặc xu hướng ẩn.
Phân tích cảm xúc (Sentiment Analysis): Xác định thái độ, cảm xúc hoặc quan điểm ẩn sau một đoạn văn bản. Doanh nghiệp ứng dụng công nghệ này để đánh giá phản hồi khách hàng, phân tích đánh giá sản phẩm, hay khảo sát nội bộ nhân viên. Một số công cụ nổi bật gồm Repustate, HubSpot Service Hub, và Google BERT – mô hình nổi tiếng trong xử lý ngữ nghĩa và cảm xúc.
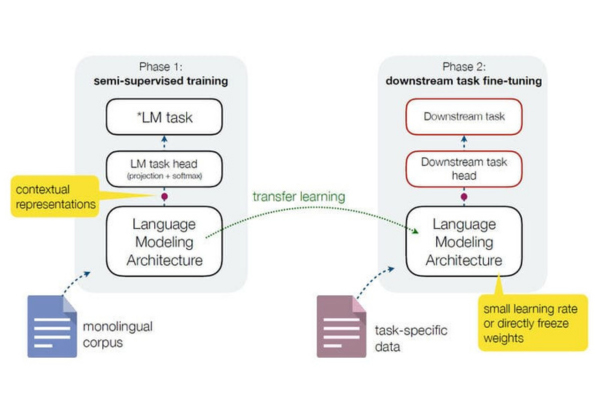
Tóm lại, Language Model không chỉ là công cụ xử lý ngôn ngữ, mà còn là nền tảng cho hầu hết các ứng dụng trí tuệ nhân tạo hiện đại, giúp máy móc hiểu, học và giao tiếp tự nhiên như con người.
Mặc dù vẫn còn những thách thức nhất định như thiên lệch dữ liệu, rủi ro lạm dụng và vấn đề đạo đức trong ứng dụng, nhưng tầm quan trọng của mô hình ngôn ngữ (Language Model) trong AI và các lĩnh vực liên quan là điều không thể phủ nhận. Sự phát triển mạnh mẽ của các mô hình ngôn ngữ lớn (Large Language Models – LLMs) đang mở ra tương lai đầy tiềm năng, hứa hẹn mang đến những bước tiến vượt bậc trong khả năng hiểu, tạo và tương tác bằng ngôn ngữ tự nhiên của máy móc.