
Trong huấn luyện mô hình học máy, dữ liệu không chỉ được xử lý một lần duy nhất mà cần được lặp lại nhiều lần để mô hình dần “học” và cải thiện khả năng dự đoán. Mỗi lần toàn bộ dữ liệu đi qua mô hình được gọi là Epoch – một khái niệm cốt lõi, được ví như “nhịp đập” trong quá trình học của trí tuệ nhân tạo. Ở bài viết này, bạn hãy cùng FOXAi tìm hiểu sâu hơn về khái niệm, ứng dụng, mối liên kết để có thể làm chủ Epoch trong huấn luyện máy học và tối ưu hóa quá trình huấn luyện mô hình của mình.
Epoch là gì?
Định nghĩa và bản chất của Epoch
Epoch là một khái niệm dùng để chỉ việc mô hình đã hoàn thành một lần duyệt toàn bộ tập dữ liệu huấn luyện. Điều này có nghĩa là trong một Epoch, mỗi mẫu dữ liệu trong tập huấn luyện đã được xử lý bởi mô hình ít nhất một lần. Sau khi hoàn thành mỗi lần duyệt như vậy, mô hình sẽ cập nhật các phép tính toán nội bộ của mình, cụ thể là các trọng số và độ lệch, dựa trên thông tin mà nó vừa tiếp thu.
Chẳng hạn như, nếu một học sinh chuẩn bị cho kỳ thi cuối kỳ với một giáo trình gồm 10 chương thì một Epoch trong quá trình học tập của học sinh đó tương đương với việc đọc và học hết toàn bộ 10 chương này một lần. Để nắm vững kiến thức, học sinh đó sẽ cần phải ôn đi ôn lại nhiều lần. Số lần ôn tập này, trong bối cảnh học máy, chính là số lượng Epoch.
Tầm quan trọng của số lượng Epoch
Số lượng Epoch là một siêu tham số quan trọng mà các kỹ sư dữ liệu phải thiết lập trước khi bắt đầu quá trình huấn luyện mô hình. Việc lựa chọn con số này có tác động trực tiếp đến hiệu suất cuối cùng của mô hình. Một số Epoch quá ít có thể khiến mô hình chưa học đủ để đạt được hiệu suất tốt, trong khi một số Epoch quá nhiều lại có thể gây ra những vấn đề nghiêm trọng khác.
Tóm lại, việc tăng số lượng Epoch sẽ giúp mô hình có thêm cơ hội để tinh chỉnh các tham số của mình, từ đó cải thiện độ chính xác hơn. Tuy nhiên, điều này cũng đồng nghĩa với việc tăng thời gian và chi phí tính toán cho quá trình huấn luyện.
Mối quan hệ không thể tách rời: Epoch, Batch và Iteration
Để hiểu sâu hơn về cách thức hoạt động của một Epoch, chúng ta cần phải phân biệt và làm rõ mối quan hệ của nó với hai khái niệm liên quan mật thiết, bao gồm Batch Size và Iteration.
Định nghĩa các khái niệm liên quan
- Batch Size (Kích thước lô): Đây là số lượng mẫu dữ liệu được xử lý cùng lúc trong một lần huấn luyện. Trong thực tế, các tập dữ liệu huấn luyện thường rất lớn, vượt quá khả năng xử lý của bộ nhớ GPU/CPU trong một lần. Việc chia tập dữ liệu thành các lô nhỏ hơn (batch) giúp quản lý tải tính toán và bộ nhớ hiệu quả hơn. Kích thước lô cũng là một siêu tham số do kỹ sư dữ liệu xác định trước.
- Iteration (Số lần lặp): Một Iteration là một bước cập nhật tham số của mô hình. Mỗi khi một lô dữ liệu được nạp vào, mô hình sẽ thực hiện một lần chuyển tiếp để đưa ra dự đoán và một lần chuyển ngược để tính toán sai số và cập nhật trọng số. Quá trình này được xem là một Iteration.
Mối liên kết giữa ba khái niệm
Mối quan hệ này được thể hiện rõ ràng qua công thức: Số Iteration trong một Epoch = Tổng số mẫu trong tập dữ liệu / Batch Size. Công thức này cho thấy rằng số lần cập nhật tham số trong một Epoch phụ thuộc trực tiếp vào kích thước của lô dữ liệu.
Ví dụ, nếu chúng ta có một tập dữ liệu gồm 1,000 mẫu và thiết lập Batch Size là 100, mô hình sẽ cần 10 lần lặp (1000 / 100 = 10) để xử lý toàn bộ dữ liệu. Khi mô hình đã xử lý hết 10 lô dữ liệu này, một Epoch sẽ được hoàn thành. Nếu chúng ta quyết định huấn luyện mô hình trong 10 Epoch, tổng số lần cập nhật tham số sẽ là 100 (10 Iteration/Epoch * 10 Epochs).
Việc lựa chọn Batch Size không chỉ đơn thuần là vấn đề quản lý bộ nhớ. Nó còn là một chiến lược quan trọng ảnh hưởng đến cách thức mô hình học. Một Batch Size nhỏ sẽ dẫn đến nhiều lần cập nhật trọng số hơn trong một Epoch. Các bản cập nhật này có thể “nhiễu” hơn, giúp mô hình có khả năng thoát khỏi các cực tiểu cục bộ tốt hơn, nhưng quá trình hội tụ có thể mất nhiều thời gian hơn. Ngược lại, một Batch Size lớn sẽ tạo ra các bản cập nhật ổn định hơn, nhưng có thể bị mắc kẹt tại một cực tiểu cục bộ không phải là tối ưu toàn cục. Điều này cho thấy sự tương tác phức tạp giữa các siêu tham số, nơi một lựa chọn tưởng chừng đơn giản lại có thể thay đổi hoàn toàn hành vi học tập của mô hình.
Để tổng hợp các khái niệm này, chúng tôi cung cấp hai bảng so sánh chi tiết dưới đây:
| Đặc điểm | Epoch | Batch | Iteration |
| Khái niệm | Một lượt đi qua toàn bộ dataset | Một tập con của dataset | Một bước cập nhật tham số |
| Vai trò | Cung cấp cái nhìn tổng quan về quá trình học | Quản lý tải tính toán và bộ nhớ | Thực hiện cập nhật tham số mô hình |
| Cách tính | Siêu tham số được thiết lập | Siêu tham số được thiết lập | Tổng số mẫu / Batch size |
| Mục đích | Đảm bảo mô hình học được toàn bộ dữ liệu | Tối ưu hiệu quả tính toán | Bước học nhỏ, lặp đi lặp lại |
Ví dụ Minh Họa Chi Tiết về Epoch, Batch Size và Iteration
| Tham số | Giá trị | Ý nghĩa |
| Tổng số mẫu | 1,000 | Toàn bộ dữ liệu huấn luyện |
| Batch Size | 100 | Số mẫu được xử lý trong một lần |
| Số Iteration/Epoch | 10 | 1000 / 100 = 10 |
| Số Epoch | 10 | Số lần mô hình duyệt qua toàn bộ dữ liệu |
| Tổng số Iteration | 100 | 10 Iteration/Epoch * 10 Epochs = 100 |
Khi Số Lượng Epoch Trở Thành “Con Dao Hai Lưỡi”
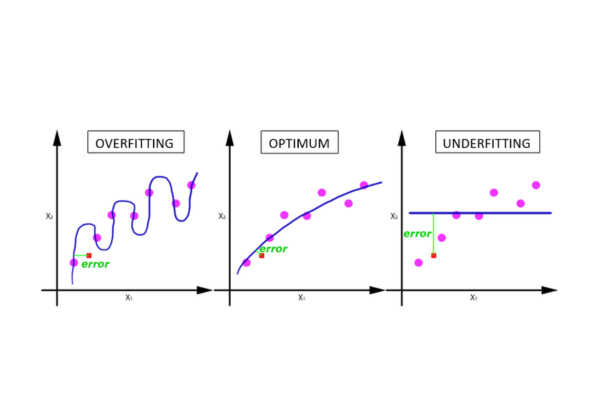
Lựa chọn số Epoch phù hợp là một trong những quyết định quan trọng nhất trong quá trình huấn luyện mô hình. Nếu không được điều chỉnh đúng cách, nó có thể dẫn đến hai vấn đề phổ biến và nghiêm trọng trong học máy: Underfitting và Overfitting.
Underfitting (Huấn luyện thiếu)
Underfitting xảy ra khi mô hình không có đủ thời gian để học các quy luật và mẫu hình cơ bản từ dữ liệu. Điều này thường là kết quả của việc thiết lập số Epoch quá ít. Mô hình hoạt động kém cả trên tập dữ liệu huấn luyện lẫn dữ liệu mới. Quay lại với ví dụ ôn thi, Underfitting giống như việc bạn chỉ đọc lướt qua giáo trình một lần duy nhất trước khi vào phòng thi. Bạn không đủ hiểu để trả lời các câu hỏi, dẫn đến điểm số thấp.
Overfitting (Huấn luyện quá mức)
Ngược lại, Overfitting xảy ra khi mô hình được huấn luyện với số Epoch quá nhiều. Trong trường hợp này, mô hình không chỉ học các quy luật mà còn học cả “nhiễu” và các mẫu không liên quan trong dữ liệu huấn luyện. Hậu quả là mô hình hoạt động rất tốt trên dữ liệu mà nó đã được thấy nhưng lại hoạt động kém hiệu quả khi gặp dữ liệu mới, chưa từng thấy trước đó. Đây là một vấn đề nghiêm trọng vì mục tiêu cuối cùng của mô hình là tổng quát hóa tốt trên các trường hợp chưa được biết.
Để hiểu rõ hơn về sự phức tạp này, cần phải nhìn vào một mâu thuẫn cơ bản: mục tiêu của việc huấn luyện mô hình là tối ưu hóa để giảm thiểu sai số trên tập huấn luyện. Ban đầu, việc tăng số Epoch sẽ giúp mô hình “tìm” ra các quy luật và giảm sai số này. Tuy nhiên, đến một ngưỡng nhất định, mô hình đã học được các quy luật chính. Tiếp tục huấn luyện chỉ khiến nó bắt đầu “học vẹt” cả nhiễu của dữ liệu. Việc “học vẹt” này làm sai số trên tập huấn luyện tiếp tục giảm, nhưng sai số trên dữ liệu mới (tức là khả năng tổng quát hóa) lại bắt đầu tăng lên. Mâu thuẫn này cho thấy mục tiêu không phải là huấn luyện cho đến khi sai số bằng 0 trên tập huấn luyện, mà là tìm ra điểm cân bằng giữa việc học hiệu quả và khả năng tổng quát hóa.
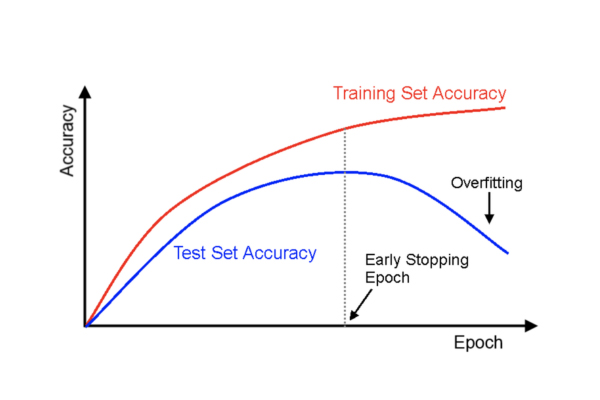
Kỹ thuật Đột phá: Early Stopping – Chấm dứt để Tối ưu
Để giải quyết triệt để vấn đề Overfitting và tìm ra điểm cân bằng lý tưởng, các chuyên gia học máy đã phát triển một kỹ thuật mang tính đột phá được gọi là Early Stopping. Kỹ thuật này hoạt động như một hình thức điều chuẩn, giúp ngăn chặn mô hình học quá mức.
Cơ chế hoạt động của Early Stopping
Thay vì huấn luyện với một số Epoch cố định, Early Stopping theo dõi hiệu suất của mô hình trên một tập dữ liệu kiểm tra độc lập (validation set). Mục đích của tập validation là cung cấp một thước đo khách quan về khả năng tổng quát hóa của mô hình đối với dữ liệu chưa được thấy.
Cơ chế hoạt động như sau: quá trình huấn luyện sẽ dừng lại sớm khi hiệu suất của mô hình trên tập validation bắt đầu suy giảm hoặc không còn cải thiện. Để đảm bảo việc dừng không phải do một dao động ngẫu nhiên, một ngưỡng “kiên nhẫn” thường được thiết lập. Ví dụ, nếu ngưỡng này là 3, quá trình huấn luyện sẽ tiếp tục cho đến khi sai số trên tập validation không giảm trong 3 Epoch liên tiếp, sau đó nó sẽ tự động dừng lại và khôi phục lại trọng số của mô hình từ thời điểm có hiệu suất tốt nhất.
Lợi ích vượt trội
Early Stopping mang lại nhiều lợi ích quan trọng:
- Ngăn chặn Overfitting: Đây là lợi ích chính, đảm bảo mô hình không học quá mức.
- Tiết kiệm tài nguyên: Dừng huấn luyện sớm giúp tiết kiệm đáng kể thời gian và tài nguyên tính toán, đặc biệt quan trọng với các mô hình phức tạp như mạng neural sâu.
- Giảm thiểu thử nghiệm thủ công: Kỹ thuật này giúp các kỹ sư không cần phải “đoán” số Epoch tối ưu một cách thủ công, thay vào đó, mô hình sẽ tự xác định điểm dừng lý tưởng dựa trên hiệu suất thực tế của nó.
Early Stopping không chỉ là một công cụ, mà còn thể hiện một sự thay đổi trong tư duy từ “tối ưu hóa cứng” (huấn luyện đủ N Epoch) sang “tối ưu hóa động”. Nó cho phép quá trình học tập tự điều chỉnh và tìm ra trạng thái tốt nhất của mô hình một cách hiệu quả nhất, cung cấp một phương pháp luận linh hoạt để xây dựng các mô hình có khả năng tổng quát hóa cao.
Lời khuyên từ Chuyên gia: Làm thế nào để chọn Số Epoch tối ưu?
Việc chọn số Epoch là một quá trình thử nghiệm và không có một con số “thần kỳ” nào có thể áp dụng cho mọi bài toán. Tuy nhiên, dựa trên kinh nghiệm thực tiễn, có một số chiến lược và lời khuyên có thể giúp bạn đưa ra quyết định chính xác hơn.
Điểm khởi đầu và điều chỉnh
Một điểm khởi đầu tốt là thử nghiệm với 300 Epoch. Trong quá trình này, bạn cần theo dõi cẩn thận hiệu suất của mô hình. Nếu mô hình bị Overfitting sớm, hãy giảm số Epoch. Ngược lại, nếu sau 300 Epoch mà mô hình vẫn chưa hội tụ hoặc chưa có dấu hiệu Overfitting, bạn có thể tăng số Epoch lên 600, 1200 hoặc nhiều hơn. Quá trình này đòi hỏi sự tinh chỉnh và quan sát liên tục.
Các yếu tố cần cân nhắc
Việc lựa chọn số Epoch tối ưu phụ thuộc vào nhiều yếu tố:
- Độ phức tạp của mô hình: Các mô hình phức tạp hơn, với nhiều lớp và tham số hơn, có thể cần nhiều Epoch hơn để hội tụ.
- Kích thước và tính chất của dữ liệu: Tập dữ liệu lớn sẽ cần nhiều Epoch hơn để mô hình học hết các mẫu, trong khi dữ liệu có nhiều nhiễu có thể cần ít Epoch hơn để tránh Overfitting.
- Các siêu tham số khác: Số Epoch cần được điều chỉnh cùng với các siêu tham số khác như Batch Size và Tốc độ học để đạt hiệu quả tối ưu. Tốc độ học quyết định mức độ cập nhật của trọng số sau mỗi Iteration. Nếu Tốc độ học quá nhỏ, mô hình sẽ cần rất nhiều Epoch để hội tụ. Ngược lại, nếu quá lớn, mô hình có thể không bao giờ hội tụ hoặc “nhảy” qua điểm tối ưu. Do đó, Epoch, Batch Size và Tốc độ học tạo thành một “bộ ba quyền lực”, nơi việc thay đổi một tham số sẽ ảnh hưởng trực tiếp đến hiệu quả của các tham số còn lại.
Kết luận
Epoch tưởng chừng là một khái niệm cơ bản nhưng vô cùng quan trọng trong học máy. Khái niệm này đại diện cho một lần mô hình duyệt toàn bộ dữ liệu huấn luyện và là một siêu tham số then chốt, liên kết chặt chẽ với Batch Size và Iteration. Việc lựa chọn số Epoch không phù hợp có thể dẫn đến các vấn đề nghiêm trọng như Underfitting hoặc Overfitting.
Giải pháp cho thách thức này nằm ở việc sử dụng hiệu quả các kỹ thuật thông minh như Early Stopping – một phương pháp hiệu quả giúp mô hình tự tìm ra điểm dừng lý tưởng, ngăn chặn Overfitting và tiết kiệm tài nguyên tính toán.
Việc làm chủ các khái niệm về Epoch, Batch, Iteration và biết cách áp dụng các chiến lược như Early Stopping là nền tảng vững chắc để xây dựng các mô hình học máy hiệu quả và tổng quát hóa cao. Hy vọng rằng, thông qua bài viết trên đây bạn sẽ có cái nhìn cụ thể hơn về Epoch và nền tảng vững chắc để lựa chọn Số Epoch phù hợp.